
Common Models
May 26, 2024
OrdersDB
Before diving into advanced Snowflake features, it's essential to have a well-structured data model to work with. Here, we'll create a basic sales-oriented data model within Snowflake, leveraging external data stored in an S3 bucket. This model will serve as the foundation for subsequent demonstrations and explorations.
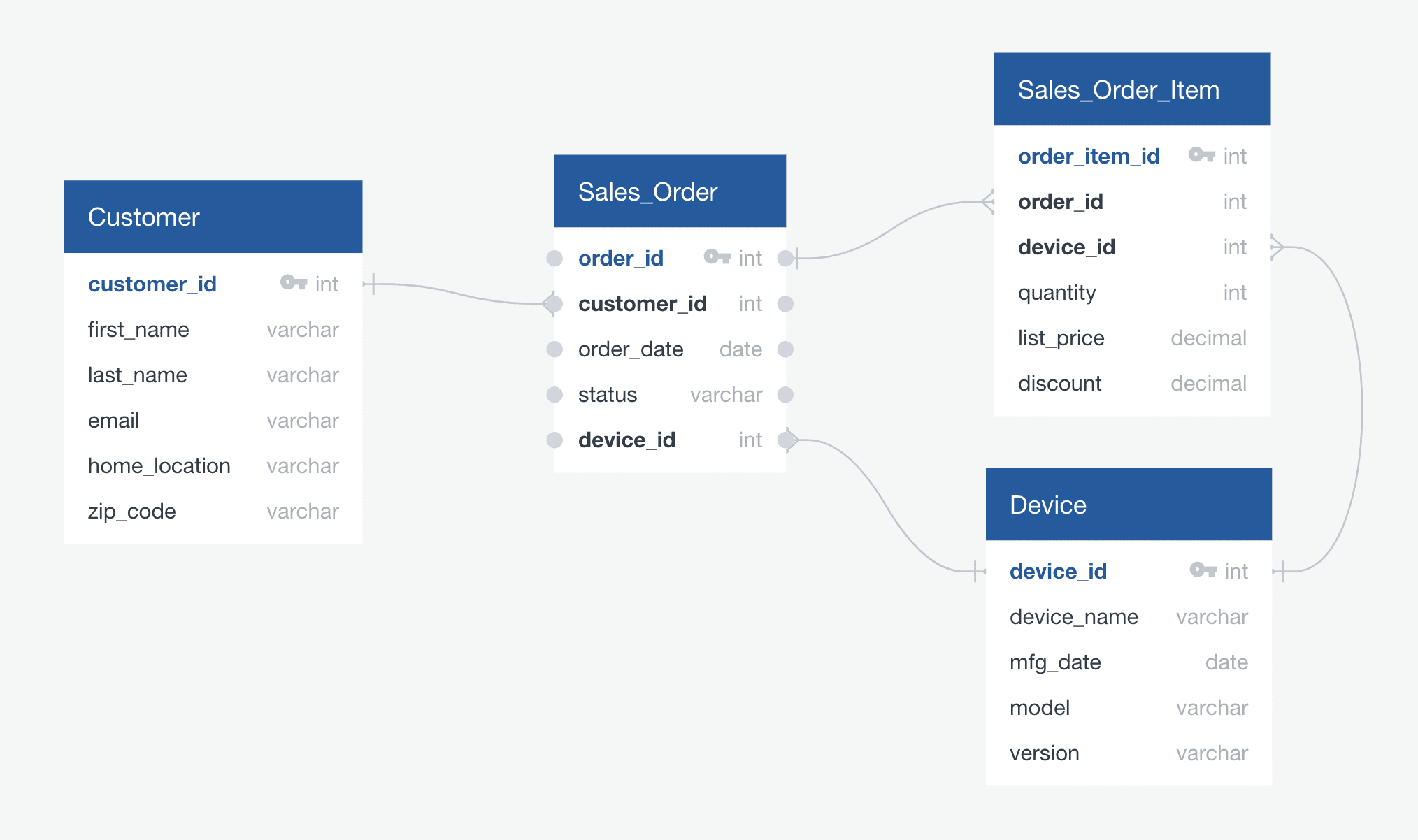
DemoHub - OrdersDB Data Model - Version 1.2.7 (updated 05/26/2024)
1. Database, File Format, and Stage Creation
>_ SQL
>_ SQL
Database (ordersdb): We begin by creating a new database named ordersdb to house all the objects related to our sales data. This organizational practice helps keep your Snowflake environment tidy and easy to manage.
File Format (CSV_SCHEMA_DETECTION): Next, we establish a file format to define how Snowflake should interpret the incoming data. This file format specifies that the data is in CSV (Comma-Separated Values) format, should parse headers for column names, skip blank lines, trim extra spaces, and be lenient towards mismatched column counts.
Stage (DEMOHUB_S3_INT): A stage is a named location in cloud storage (in this case, an S3 bucket) where Snowflake can access your data files. This stage points to the demohubpublic/data/ directory on S3, from which we'll load our sample data.
2. Loading Data with Schema Inference
>_ SQL
Schema Inference (INFER_SCHEMA): Snowflake's powerful INFER_SCHEMA function examines the files in your S3 bucket and automatically determines the appropriate columns and data types for your tables. This saves you the manual effort of defining the schema.
USING TEMPLATE: This clause creates a table based on the inferred schema. It's a convenient way to avoid writing explicit CREATE TABLE statements with detailed column definitions.
ARRAY_AGG and OBJECT_CONSTRUCT: These functions are used to transform the inferred schema information into a format suitable for creating the table.
3. Adding Constraints and Referential Integrity
>_ SQL
Primary Keys: Unique identifiers are established for each table (device_id, customer_id, order_id, order_item_id) to ensure data integrity and enable efficient lookups.
Foreign Keys: Relationships between tables are defined to maintain data consistency. For example, a foreign key constraint on sales_order(customer_id) references customer(customer_id), guaranteeing that every order is linked to a valid customer.
4. Copying Data into Tables
>_ SQL
COPY INTO: This command efficiently loads the data from your S3 bucket into the corresponding tables.
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE: Ensures smooth data loading even if there are minor inconsistencies in column name casing between your CSV files and table definitions.
Ready for Exploration
With your data model set up and populated, you now have a playground to explore Snowflake's advanced features like data classification, masking, forecasting, anomaly detection analysis and much more.
This sales data model enables a wide range of analyses, including:
Customer Insights: Analyze customer demographics, purchase history, and lifetime value.
Sales Performance: Track sales trends over time, identify top-selling products, and evaluate the effectiveness of different sales channels.
Inventory Management: Monitor stock levels, analyze product popularity, and optimize inventory based on sales patterns.
Order Analysis: Examine order details, shipping information, and customer satisfaction metrics.
Predictive Modeling: Develop models to forecast future sales, predict customer churn, or identify potential upsell opportunities.
This data model will be referenced in subsequent demo’s as we delve deeper into Snowflake's capabilities.




