
Advanced Data Warehousing
Jun 30, 2024
Snowflake Memoizable Functions
Did you know Snowflake provides a powerful tool to supercharge your query execution times? It's called Memoizable Functions! Especially useful when handling complex calculations or repetitive data transformations, these functions intelligently cache results. This means they drastically reduce the need to recompute the same outputs multiple times, leading to significant performance gains.
What are Snowflake Memoizable Functions?
Memoizable functions in Snowflake are a special type of user-defined function (UDF) that caches their results based on the input arguments. The first time the function is called with a specific set of arguments, it calculates the result and stores it in the cache. Subsequent calls with the same arguments simply retrieve the result from the cache, bypassing the need for recalculation.
Why Memoizable Functions Matter
Performance Boost: For computationally expensive or time-consuming calculations, memoizable functions can dramatically improve query performance by avoiding redundant computations.
Cost Savings: Since memoizable functions reduce the compute resources required, they can lead to cost savings in your Snowflake environment.
Enhanced User Experience: Faster query response times translate to a more responsive and efficient user experience.
When to Use Memoizable Functions
You might be wondering, "This is all good information, Fru, but when and where will I ever need to use memoizable functions in real-world scenarios?"
Beyond the practical example of improving performance for complex UDFs, consider these specific use cases within Snowflake's governance and policies framework:
Row Access Policies (RAP): RAPs often involve complex logic to determine whether a user has access to specific rows based on their attributes or roles. Memoizing the access control logic can avoid redundant computations for the same user across different rows, improving policy enforcement performance.
Column Masking Policies: Masking sensitive data based on user roles or attributes can be computationally expensive. Memoizing the masking logic for specific users or data combinations can significantly speed up the masking process, especially for large datasets or frequent queries.
Data Classification Policies: Classifying data into different sensitivity levels might involve complex rules and lookups. Memoizing the classification logic for specific data values or attributes can streamline the classification process and reduce the overhead of repeated calculations.
Dynamic Data Masking: When masking policies depend on external factors (e.g., user location, time of day), memoization can cache masking results for specific contexts, avoiding recalculation whenever the same context is encountered.
Here is an excellent post by Felipe Hoffa with practical examples — check it out: Faster Snowflake UDFs and policies with ‘memoizable’ | by Felipe Hoffa
Practical Example: Customer Lifetime Value (CLTV)
Let’s illustrate the power of memoizable functions using a real-world example from the OrdersDB data model (setup the model in your practice environment if you haven’t done so already).
Next, imagine you want to calculate the Customer Lifetime Value (CLTV) for each customer. This calculation involves aggregating purchase data over time and applying a discounting factor.
Non-Memoizable Function:
Memoizable Function:
Testing and Comparing Performance
To measure the performance difference, we would run several tests to compare the execution times, using query profile.
Test Results
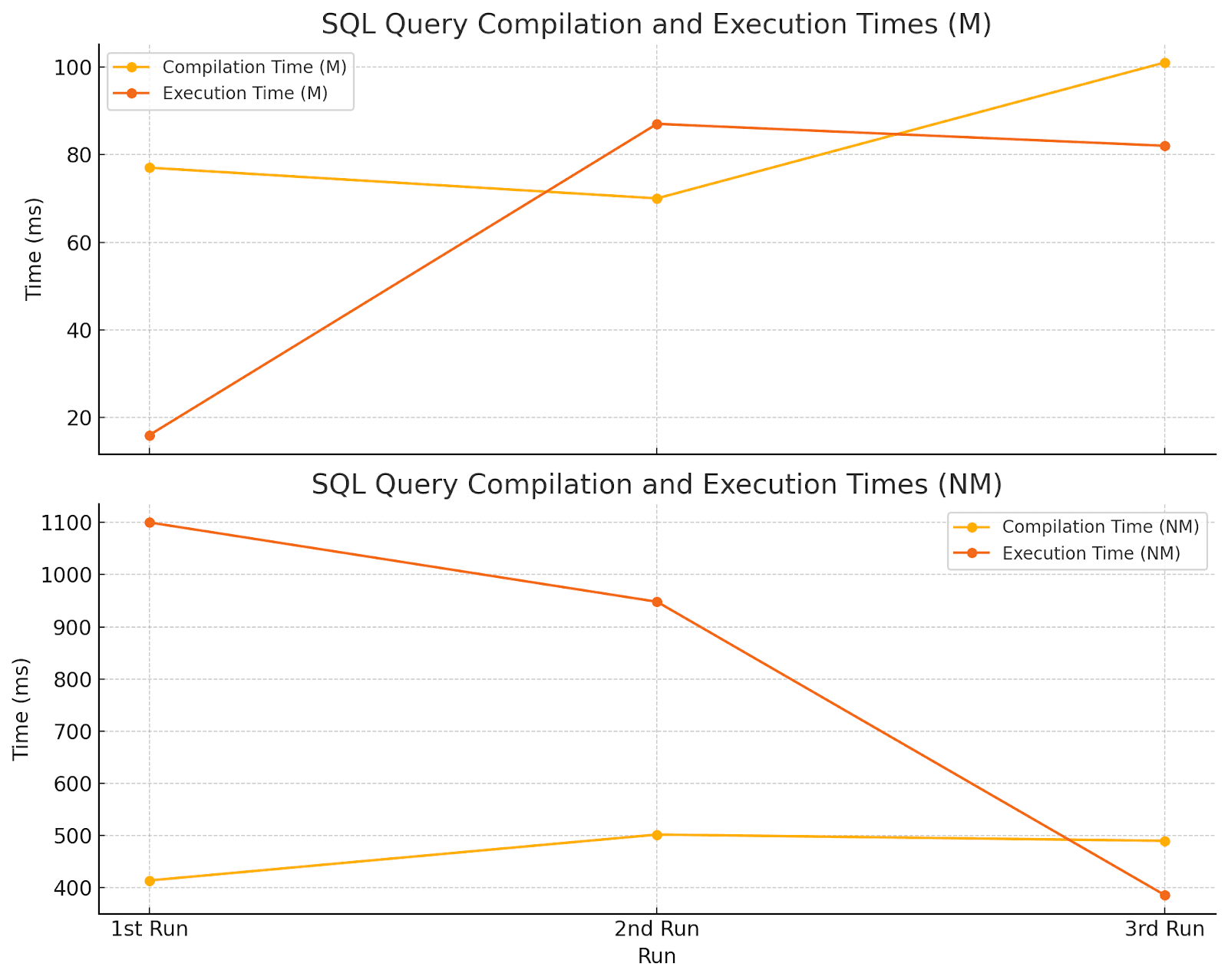
Here are the graphs plotting just the compilation and execution times for both datasets (M - Memoizable and NM - Non Memoizable): Note - I ignored plotting the Total Execution time as I think the values in the UI aren’t correct. Summing the Compilation and Execution times did not match the Total Times for the M runs. That’s probably a bug to be looked at.
Key Observation
As indicated in the results above; by running both queries multiple times and comparing the results, you'll likely observe a significant performance improvement when using the memoizable function, especially for larger datasets or when the function is called repeatedly with the same inputs.
Non-Memoirized

1st Non-Memoirized:
Query Profile
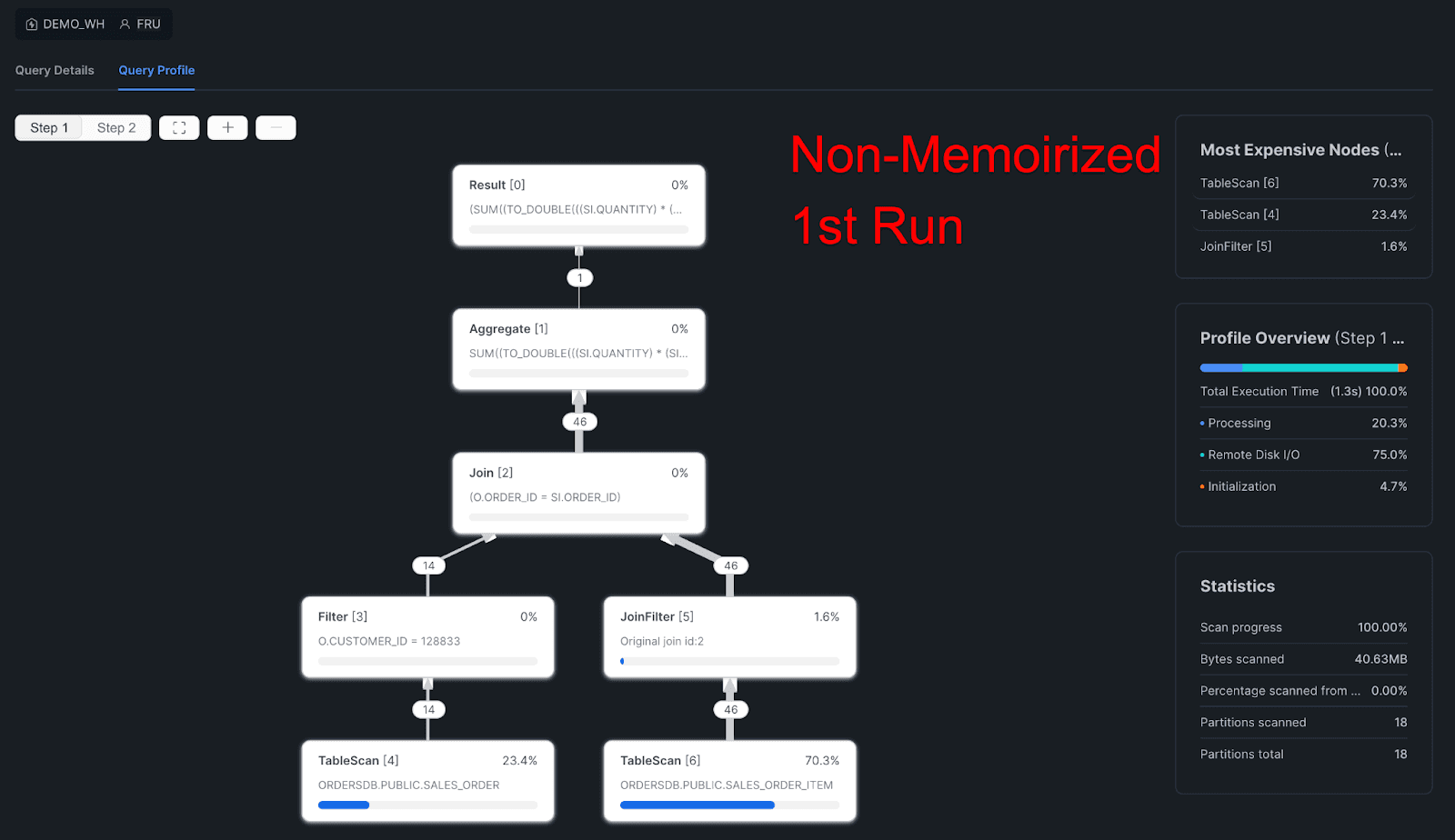
Query Details
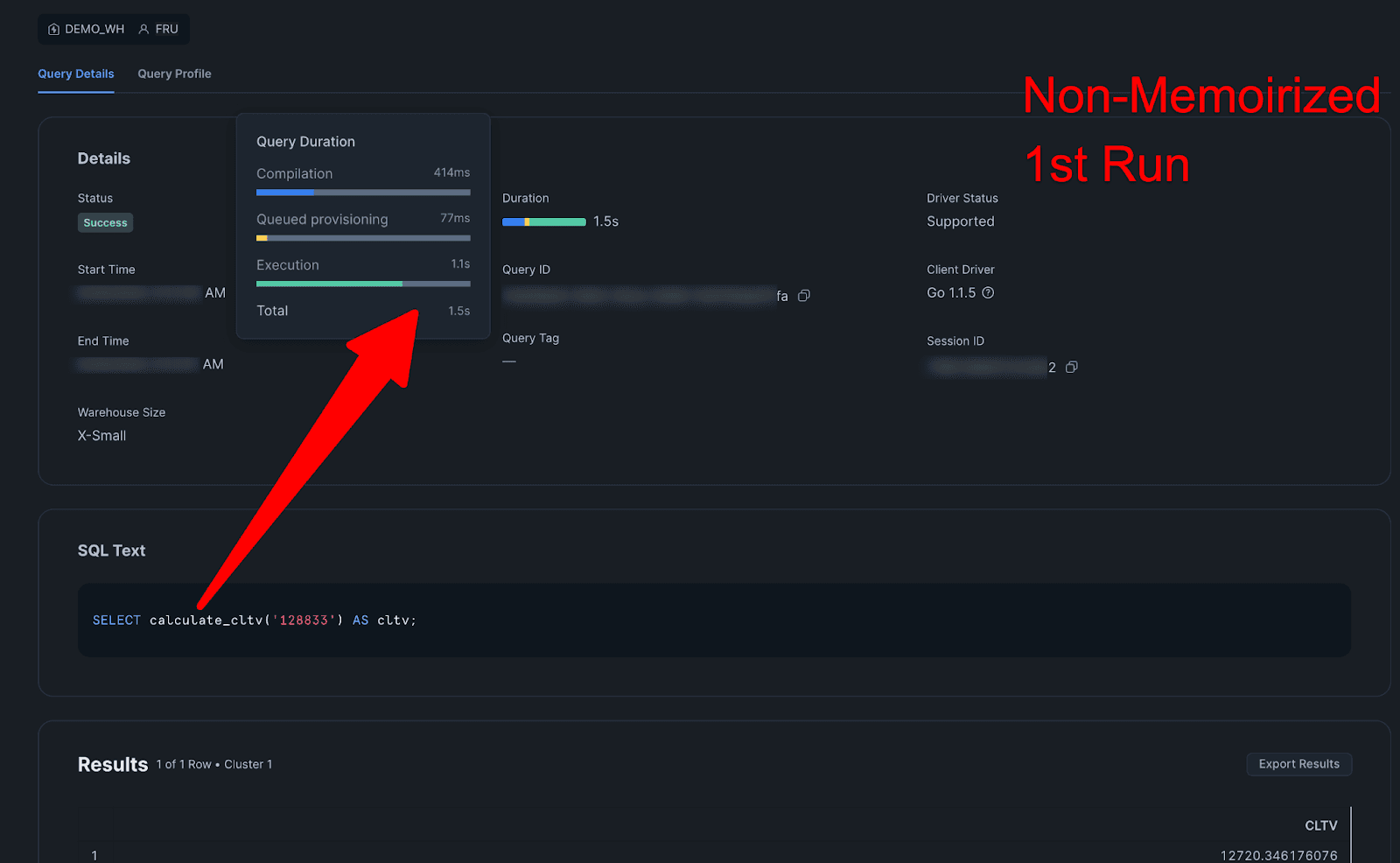
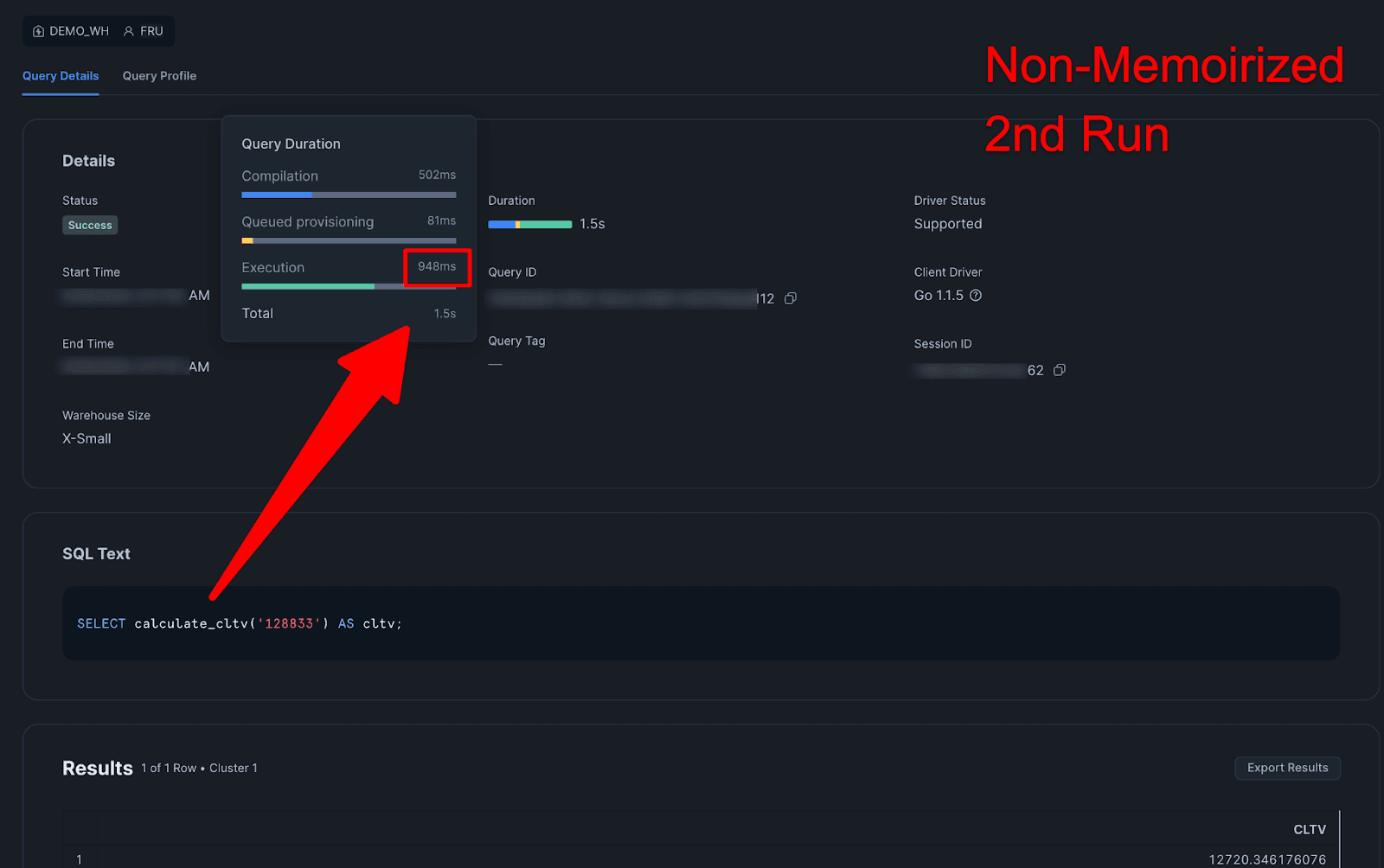
2nd Non-Memoirized:
Query Profile
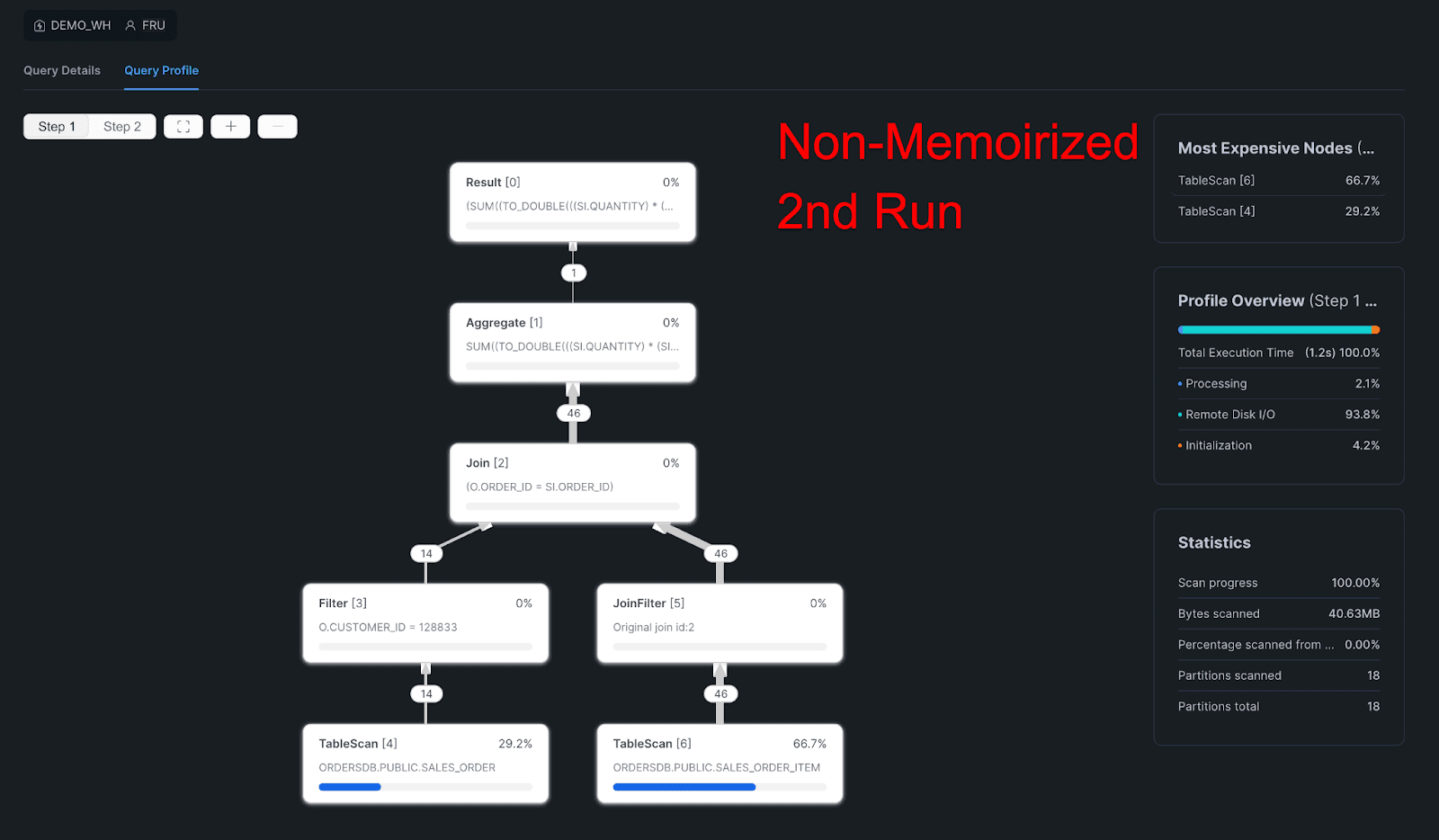
Query Details
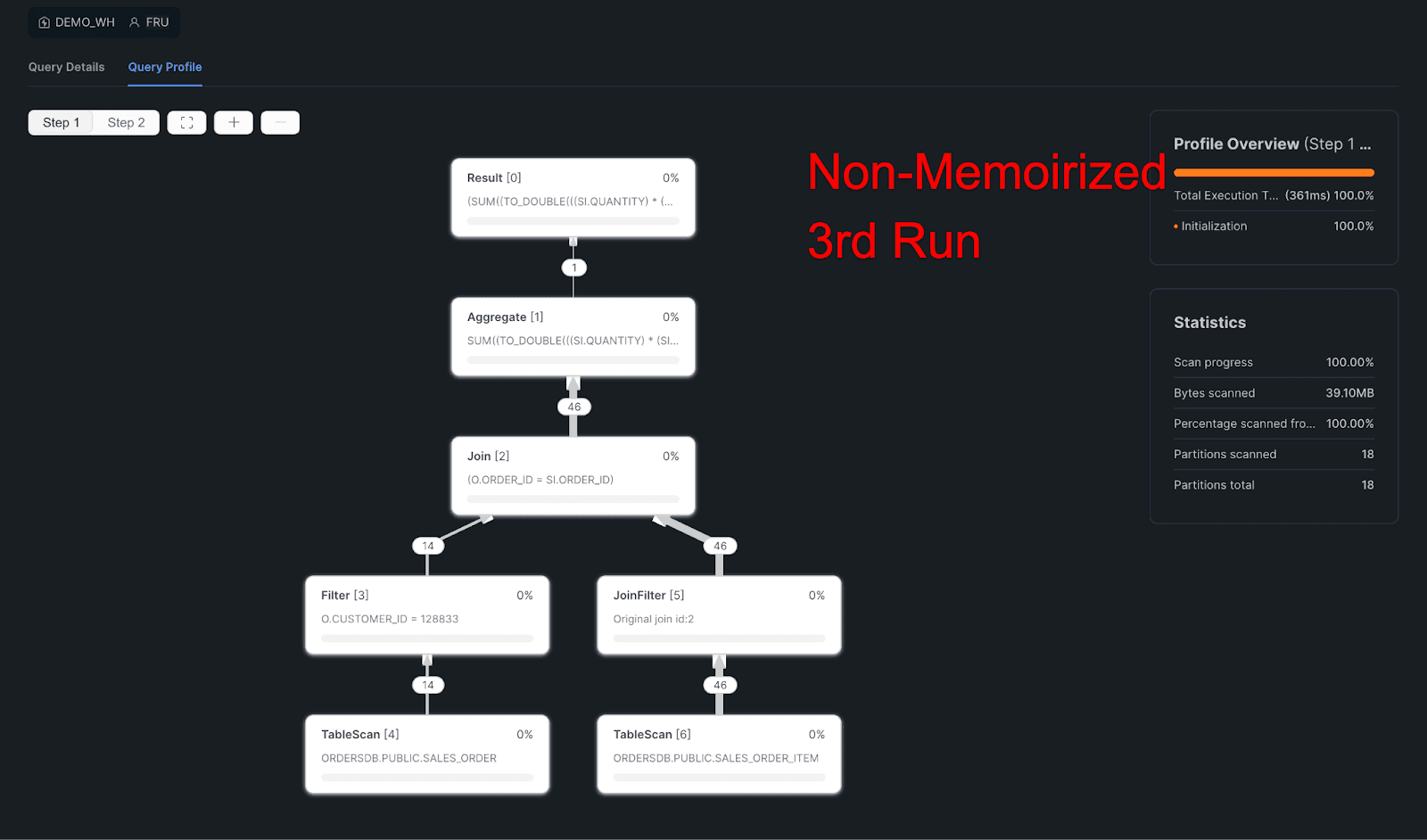
3rd Non-Memoirized:
Query Profile
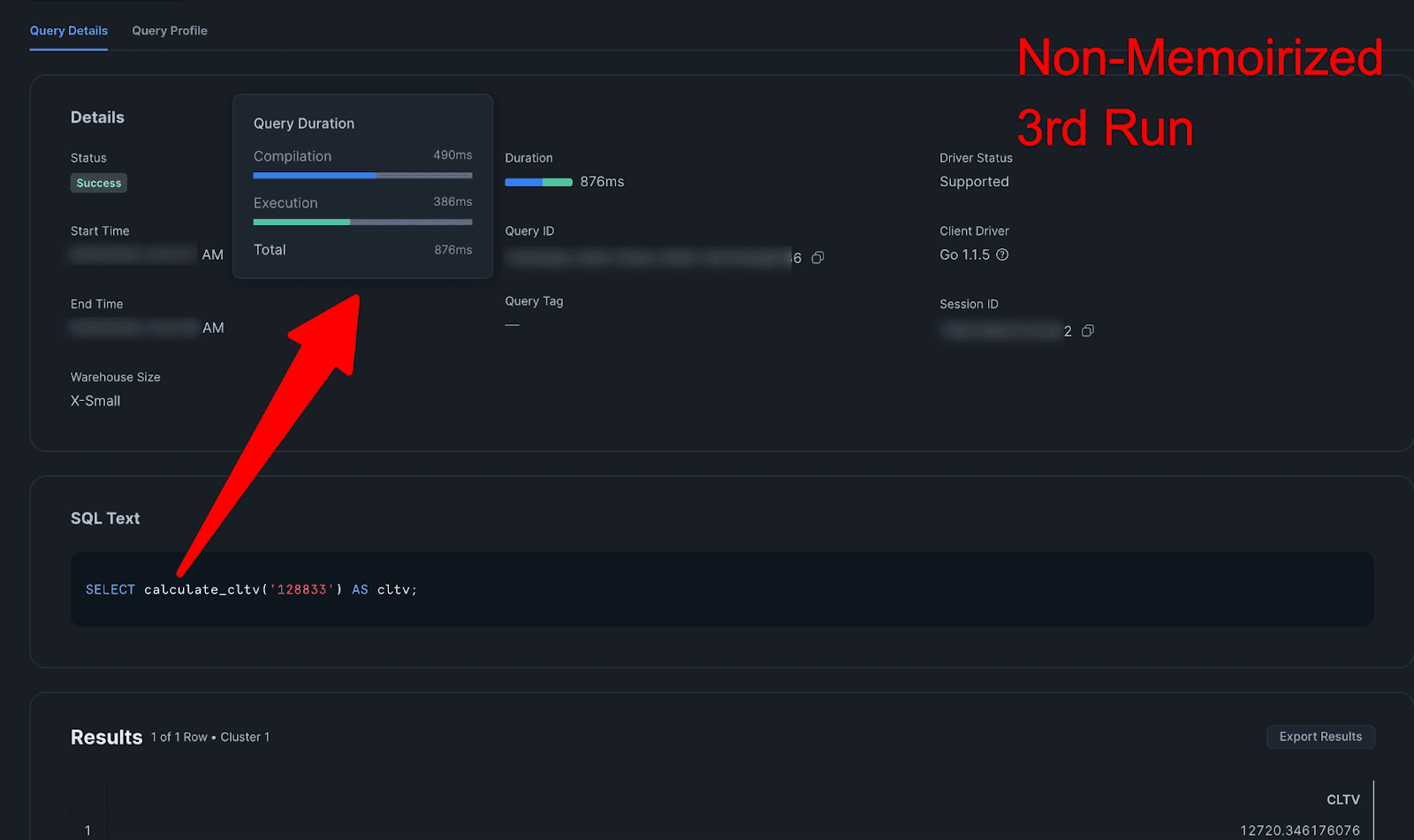
Query Details
Memoirized

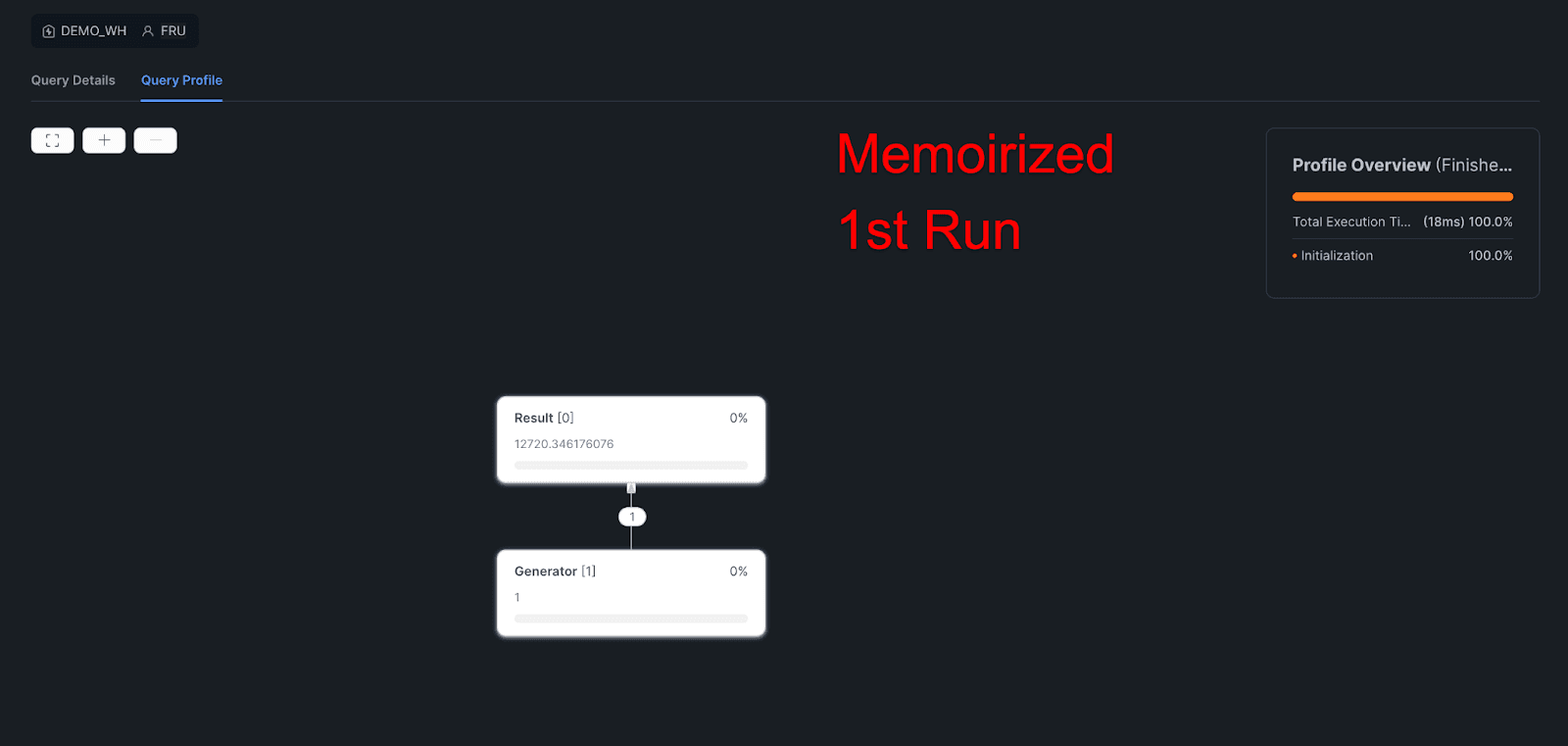
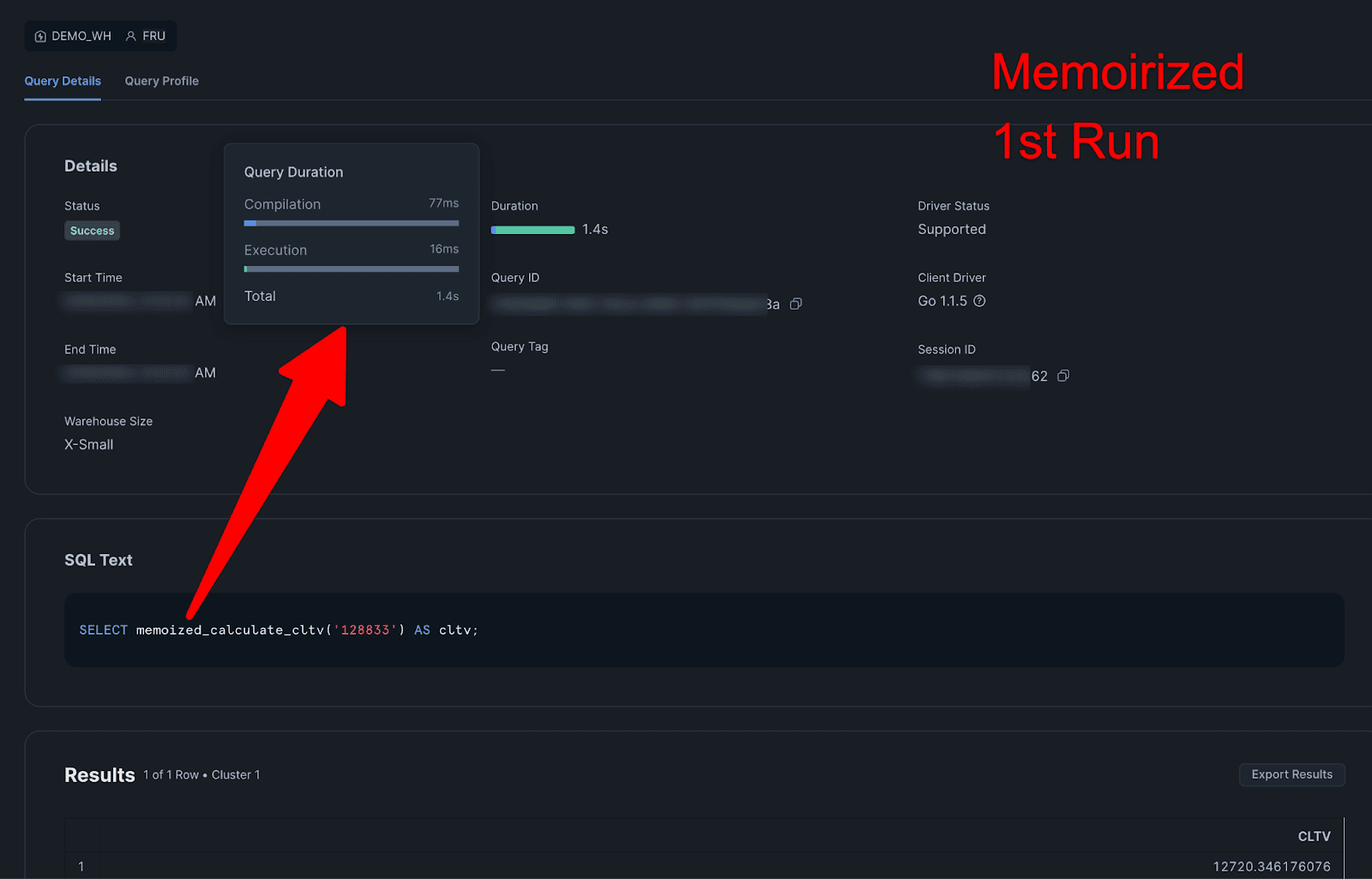
1st Memoirized:
Query Profile
Query Details
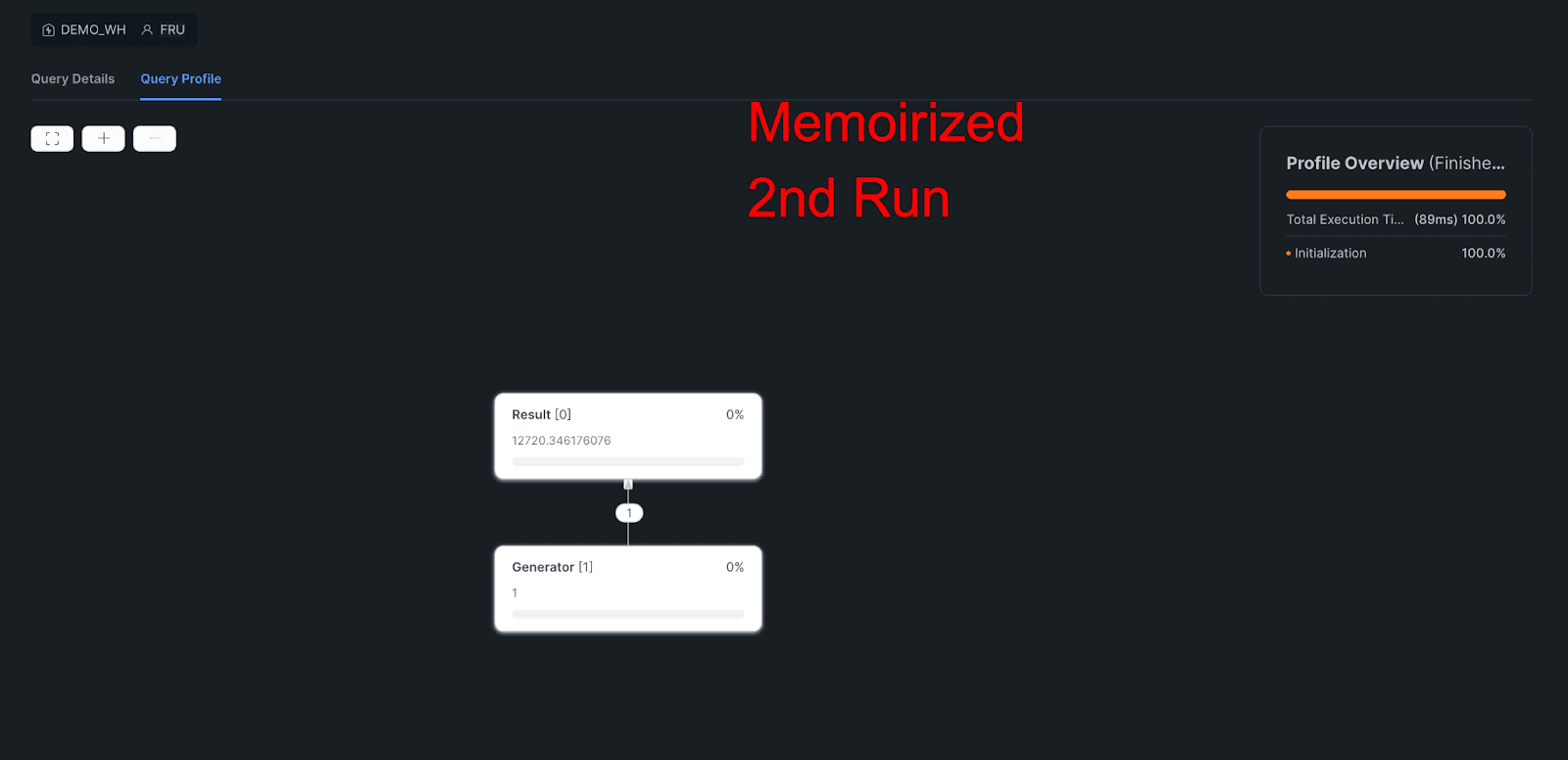
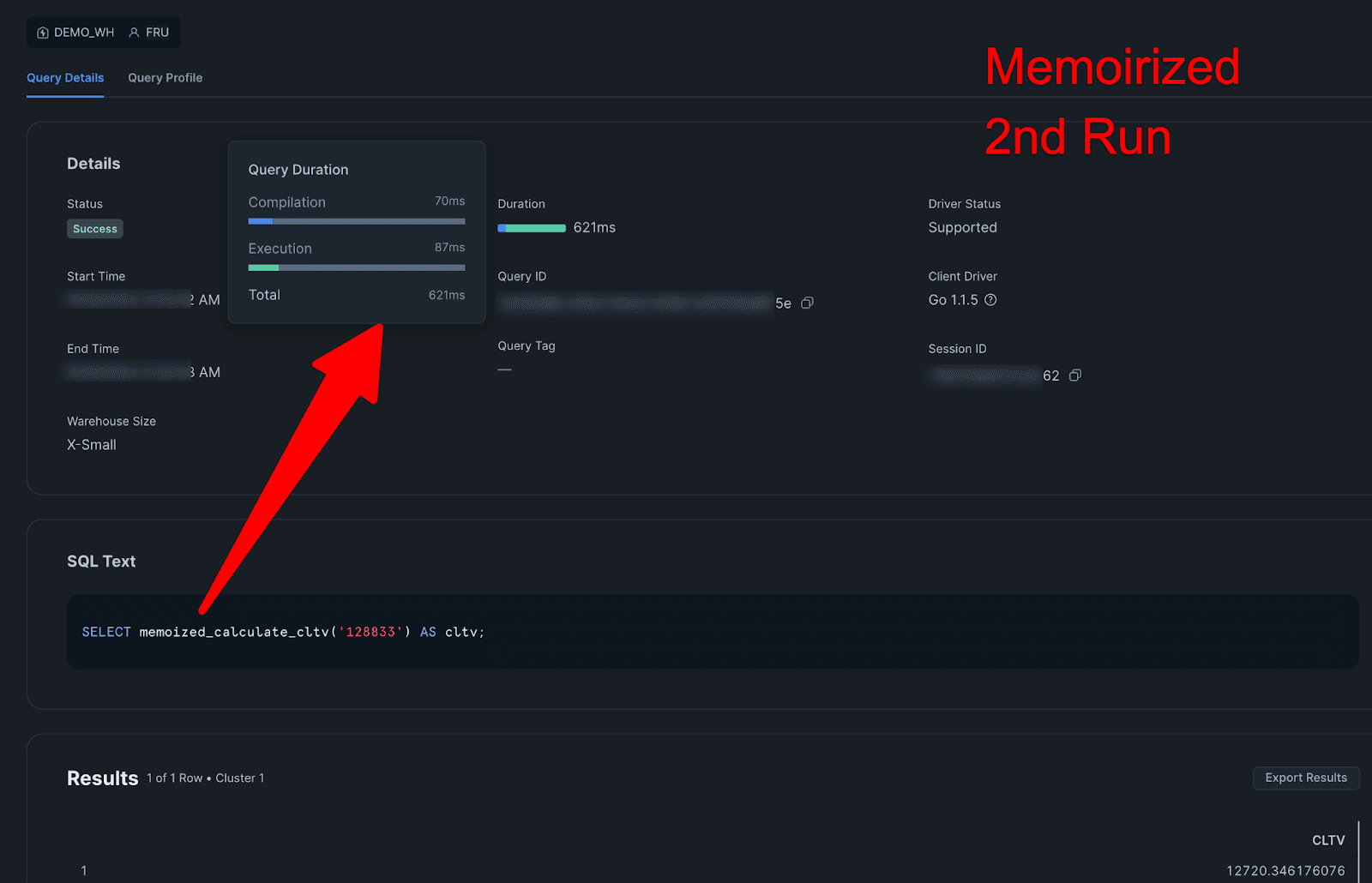
2nd Memoirized:
Query Profile
Query Details
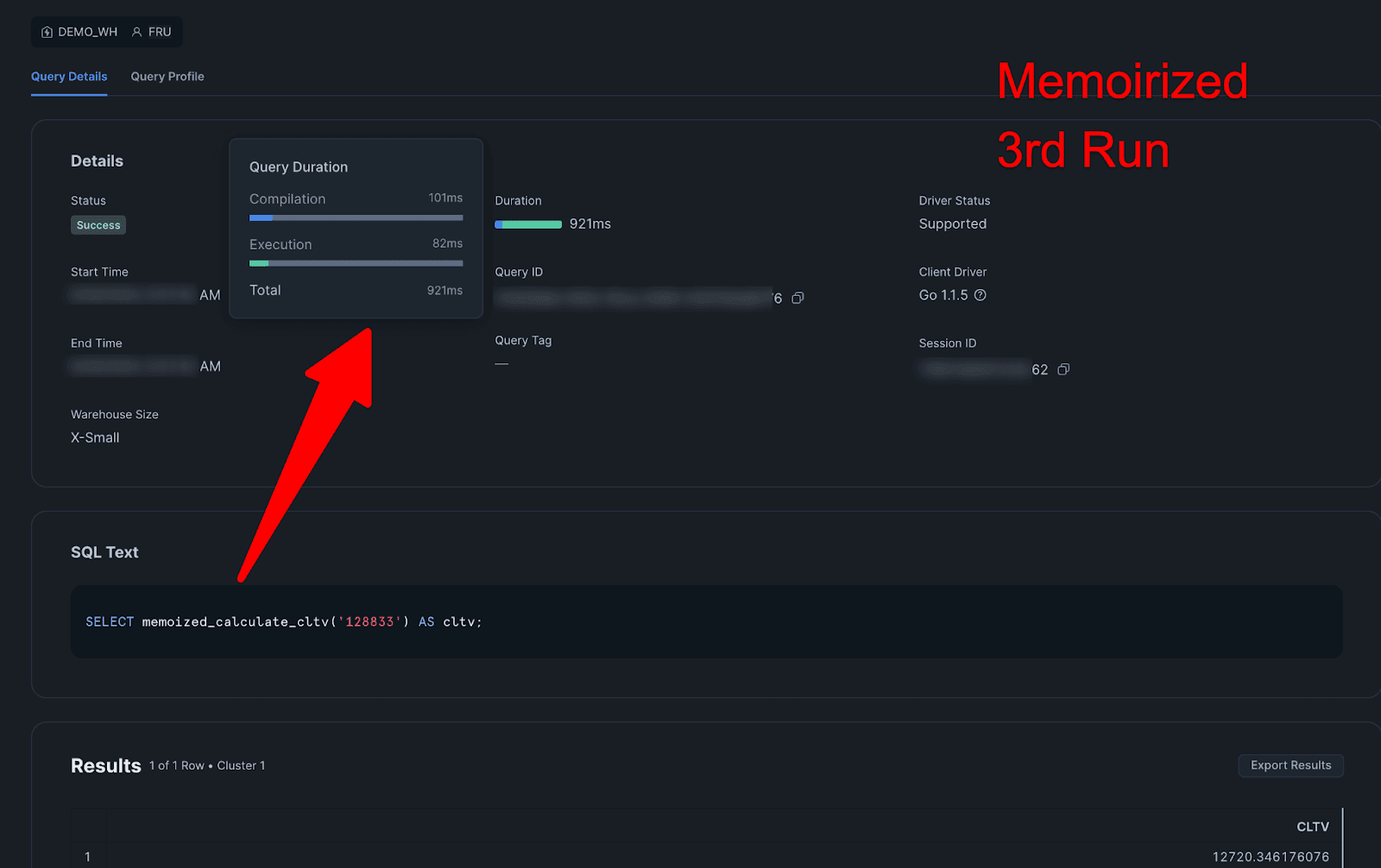
3rd Memoirized:
Query Profile

Query Details
Explanation:
The MEMOIZABLE keyword tells Snowflake to cache the results of the function based on its input arguments (customer_id in this case).
The first time the memoizable function is called with a specific customer_id, it will execute the query and store the result in the cache.
Subsequent calls with the same customer_id will directly retrieve the result from the cache, avoiding the need for recomputation.
Caching Differences (Regular Cache vs Memoizable Cache)
Snowflake's caching mechanisms play a crucial role in optimizing query performance and reducing resource consumption. While both regular Snowflake caching and memoizable functions aim to store results for faster retrieval, they have distinct differences in how they work and when they're most effective.
Regular Snowflake Caching (Result Cache)
Scope: Works at the query level. It caches the results of entire queries or subqueries.
Trigger: Triggered automatically by Snowflake based on various factors like query text, warehouse size, and data changes.
Persistence: Cached results are typically stored for a limited time (default: 24 hours) and can be evicted based on factors like data updates or cache pressure.
Benefits: Improves the performance of repetitive queries and reduces warehouse load.
Use Cases: Ideal for frequently executed queries with relatively stable data.
Memoizable Functions
Scope: Works at the function level. It caches the results of specific function calls based on their input arguments.
Trigger: Triggered explicitly by the MEMOIZABLE keyword in the function definition.
Persistence: Cached results remain in memory as long as the function exists, even across sessions.
Benefits: Significantly improves the performance of complex or computationally intensive functions that are called multiple times with the same inputs.
Use Cases: Suitable for deterministic functions (where the output is solely determined by the input) that are frequently used with the same arguments.
Important Considerations
Automatic Cache Invalidation: Snowflake automatically invalidates the cache for memoizable functions when underlying data changes, ensuring the results remain up-to-date.
Manual Cache Invalidation: You can manually invalidate the cache if needed, for example, if you want to force a recalculation or clear the cache to free up memory resources.
Memory Usage: While memoization can improve performance, it's important to be mindful of the amount of data cached. Excessive caching can consume memory resources and may negatively impact overall system performance. Monitor the memory usage of your memoizable functions and adjust the caching strategy if necessary.
By incorporating memoizable functions into your Snowflake workflows, you can achieve significant performance optimizations, particularly for scenarios involving complex calculations or frequent function reuse. This can translate to cost savings and a more responsive user experience.









